Large Language Models (LLMs) such as ChatGPT or Llama require very powerful and expensive hardware to function properly. These costs are particularly relevant if a company wants/needs to run LLMs on its own servers due to security and data protection requirements.
Running a language model with the same quality of ChatGPT within your own company requires expensive hardware.
But don’t worry, there is an optimization: Quantization can drastically reduce the hardware requirements of LLMs (up to 80%). In this post, I’ll explain how it works.
Quantization of LLMs simply explained
“What time is it?” Few of us would probably answer “10:21, 18 seconds, 700 milliseconds and 3 nanoseconds” to this question, right?
Most would probably be satisfied with the approximation “10:21”.
What we do here in our everyday lives is, in its simplest form, the same thing that happens with quantization in AI models: We leave out unnecessary information.
But what about a stopwatch? If we want to measure how long it takes a runner to cover 100 meters, then “0 hours and 0 minutes” would probably be too imprecise. In this case, we need more precise information. The seconds and milliseconds are usually also specified here. “0 hours, 0 minutes, 10 seconds, 300 milliseconds”.
So it depends on the application how precisely you measure the time. This is also the case with AI models. The providers first train an AI model as accurately as possible (analogous to our example: including seconds, milliseconds and nanoseconds). But this accuracy comes at a price: we have to store and process a lot of information.
If we don’t need such precise answers, we can optimize here.
In other words, we leave out just enough information so that our final result is hardly affected (because we don’t need to know the exact time in milliseconds). In this way, however, we can save a massive amount of resources.
Introduction to the quantization of LLMs
Similar to our clock example from the introduction, quantization in LLMs is a technique used to reduce the accuracy of AI models to a relevant level by reducing the accuracy of the parameters (mainly the weights).
For example, instead of using 16-digit floating point numbers, the weights can be reduced to 8 digits or even 4-digit integers without any significant loss (more on how this is measured in the section “Perplexity as a performance measure”) in model accuracy.
The quantization process then looks like this:
1. Before, we have the weights within the models (what ultimately constitutes the intelligence of the model) in full precision. This high precision costs us 16 memory locations per weight
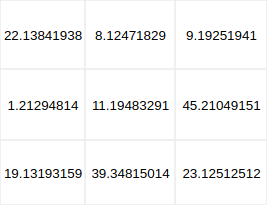
2. If we now reduce these weights to fewer digits, we save memory space.
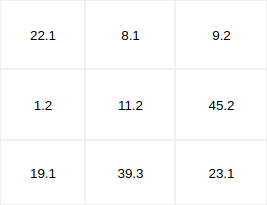
3. Now there is another trick: decimal numbers are much more difficult for computers to process than integers (numbers without a decimal point). So we also convert the weights into integers. (By multiplying all values by 10) The weighting between the values is still exactly the same, but we now have them in an optimal format for the computer and can thus achieve further speed gains.
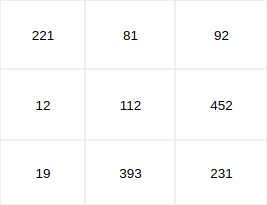
Now we need to look at how the accuracy of quantized models can be evaluated. Of course, it doesn’t help if we now have a quantized model that no longer meets our requirements.
Perplexity as a performance measure
Perplexity is a measure of the uncertainty of a language model in predicting the next word. It works quite simply. As explained in our article on expert parameters in ChatGPT, all a language model does is predict the next word. Perplexity is used to measure how well the model predicts the next word. For example, if we want to predict the sentence “An apple tastes sweet”, we enter “An apple tastes” into the language model and measure the probability with which it predicts the word “sweet”. We now do this with many different sentences and can measure how often a (quantized) model is wrong. This gives us the perplexity. (For a deeper introduction to mathematics, we recommend this article)
A low value for perplexity indicates that the model has grasped the language and can predict the next word in a sequence with a high degree of certainty. Conversely, a high value indicates greater uncertainty and difficulty for the model, which can lead to less accurate or relevant text generation.
It is always surprising how small the differences in perplexity are in quantized models compared to the original models.
Here is a table showing the small differences in perplexity between different quantizations of the ‘Llama 3 8B’ model.
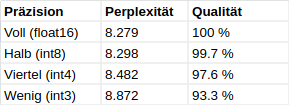
As can be seen, the quantized models are surprisingly close to the quality of the original “float16” model. It can be said that the int8 models are almost as good as the original. Only the very strongly quantized models (int4 & int3) should be tested more carefully to see whether they are good enough for the intended purpose.
Funfact: The excellent result for int8 suggests that Meta has already worked with an “int8 quantization” when training the model.
Why not just use a smaller model directly?
Think of the parameters of a model (e.g. 13 billion or 30 billion) as the depth of knowledge. The more parameters, the more information the model originally learned and stored. Models with a higher number of parameters have a deeper understanding and can make better, broader and more “creative” connections between the information they have learned. Conversely, a smaller model has less knowledge available and is worse at answering questions.
Quantization, on the other hand, can be thought of as a question of the accuracy with which this information can be connected. A highly quantized model may still know a lot, but can no longer make the connections.
To put it bluntly: If you want to build a rocket to the moon and you have to choose between a sophomore aerospace student (small model) or his experienced but drunk professor (quantized large model), which would you choose?
That’s the trade-off: Small model if we need less knowledge but need to understand strong connections within that knowledge. Large, quantized model, if we want to access a lot of knowledge, but the connections may not be quite so important (so it’s okay for the drunk professor to talk a bit confused in between, as long as she comes up with the solution in the end). Large, quantized models have proven to be better for chat applications.
Conclusion
A quantized (cheaper) model is the better option for most use cases, as it saves server resources and therefore costs.
As we have seen, quantized models continue to deliver very good results.
And if you are looking for a partner who can host an (quantized or not) LLM in-house at your company in a data protection-compliant & cost-efficient manner, then please get in touch with me: llms@simon-frey.com