Read this article BEFORE you pitch Pinecone, Qdrant, Weaviate, LanceDB,… to your boss.
For this article, I assume you know what a vector database/index is. If not, please check out this article explainer article by Pinecone (you will see later why me linking to them is so ironic)
We have to talk about a technology emerging on the sidelines of the entire AI hype: vector databases. In this article, I won’t go in-depth into what a vector database is; there are others who have done this in great depth. No. I will explain to you why I think vector search is a feature, and should not be a dedicated database in your applications stack.
To get the obvious question out of the way: This article is NOT about me hating vector databases. Vector search and indices are great technologies that will improve a lot of products. And quite likely, you will find a way to get value from them in your software. (Did I mention, you can work with me to find out how to use vector search for your company)
This article presents you my reasoning why I think dedicated vector database products (and the startups behind them) such as Pinecone, Qdrant, Weavitate, LanceDB are doomed fail.
Let’s assume we want to improve product recommendations for an online shop. In order for the shoppers to buy more, we want to recommend related products. This is a big lever for the business to increase cart value and hence revenue.
Most online shops use some ineffective “other products in the same category” algorithms for this. So we, as savvy developers, want to come in and improve these recommendations. As we heard from Reddit and HackerNews, vector search is the way to go. What do we do?
First, we need to decide what dimensions/properties our vector space should represent. Let’s stay with the basics:
- Product Category
- Product Keywords
So far, we would not need vector search as we use the same properties as the static algorithm. So let’s add more information, which we parse from past purchases:
- Predominant Gender buying this item (Cold. For this, we still don’t really need a vector search)
- Product title (Warm. We could still do this with a basic full text search, as titles tend to be short enough).
- Product description (Jackpot! This information is hard to embed in a static algorithm. Here we can benefit from text embeddings and vector search.)
Good. We found a valuable use case for a vector search. Built text-embeddings for our product descriptions. And added the other properties as one-hot-encoded vectors. The research is done and we are ready to go into the development phase….
And FINALLY we come to the point that this article is actually about: What technology should we use to store and search our vector embeddings? We research this question and find tens of listicles on Google all telling us that either Pinecone, Qdrant, Weaviate or LanceDB are the way to go. Wrong!
The best vector database is the database you already have. I would even go further and say the best database for anything is the database you already have.
Introducing a new core piece of technology into your stack comes with a lot of potential downsides, which are not obvious at first sight. To me, the most relevant downsides of introducing a new database into your infrastructure are the following:
- Stability. As someone being paged in the middle of the night for rescuing a burning database, I can tell you: There are always things you will oversee and which will bite you later. This usually happens during peak traffic and outside of regular business hours. IT IS HARD TO RUN A DATABASE.
- Backups & Recovery: If you introduce a new core piece of technology in your stack, keep in mind to do regular maintenance, backups and recovery drills. This is overhead, which will cost your team a significant amount of time.
- Knowledge distribution: Even if you spend time to become an expert in the shiny new vector database you opted for, you are now the only person on the team who understands what is going on. You need to onboard your colleagues to this new technology as well. And this doesn’t stop at the current team…for every new hire that joins your team, you repeat that process.
- SaaS is not the rescue: The popular vector databases offer a SaaS model. First, it is a good decision to not host the database yourself. Second, be aware of two core problems.
- Cost: Usually managed databases are cheap at first, but later when you are locked in the cost skyrockets. This is the Oracle model, it makes sense, but be aware of it. (Again: Got bitten by this. I write my articles so you don’t have to repeat my mistakes)
- Counter-party risk: These vector database startups are building on the current AI hype and venture capital cash. If the startup runs out of cash (as I expect most of them do), you are now stuck between a rock and a hard place. You must either switch the database technology (once again), or migrate to a self-managed variant of the database (What you tried to prevent in the first place).
- Local reproducibility: Having a second database to manage in the local developer setup, makes it more difficult to use and can affect developer productivity
Alright. We talked about the downsides of introducing a dedicated vector database into your stack. But on top, let me amphesize this once again: You already have a database, it 99.9% already is capable of doing vector search. JUST USE WHAT YOU HAVE.
Here are the 10 most popular database systems (March 2024, according to db-engines.com) supporting vector search. Quite likely you are already using one of these. Every single one of them is capable of storing vectors and doing a nearest-neighbor search on them (which is all you need). Every single one of them…
- Oracle DB: Oracle Introduces Integrated Vector Database
- MariaDB: MariaDB Vector
- PostgreSQL: pgvector
- MongoDB: Vector Search
- Redis: Vectors
- ElasticSearch: Vector search
- IBM Db2: How IBM Is Turning Db2 into an ‘AI Database’
- Snowflake: Use AI in Seconds with Snowflake Cortex
- SQLite: Introducing sqlite-vss: A SQLite Extension for Vector Search
- Cassandra: Vector Search Quickstart
You already have a database in your product that is able to do vector search, please use it. PLEASE. It will save you weeks of headaches, is already (hopefully) running stable, is being backuped, access controls are battle tested, and your team knows how to use it.
Given, I paint a really black-and-white picture here as this is an opinionated article to bring home one point: Use boring technology and sleep well at night.
One more aspect we have to talk about is filtering.
For most of the use cases I am exposed to, we are not only interested in finding top-k results, but also in applying hard filters to the results.
In our e-commerce shop example: We don’t want to recommend items that are not in stock anymore. If we use the same database for the vector search as the one where our stock information is stored in, this is as simple as a single JOIN , it is trivial.
If we have a dedicated vector database, we either have to keep the stock data up to date in two places, which is a common source for errors. Or cross-reference the results of our vector database against our main database Both scenarios introduce extra logic & latency in comparison to our “one database to rule them all” option.
The only time a dedicated vector database can make sense? If your vector search is in the non-critical path.
You have to ensure that the extra load that you put on your database with vector search is not impacting it in a bad way. Indeed, it will add more load to your database instance.
When you consider your vector search as a non-critical part of your application workflow, it might be a good decision to put it onto a dedicated database instance. For the case that your vector search runs hot, it does not drag down the rest of the application.
But here, I would advise you to go for a second instance of the same database you already have (e.g. PostgreSQL with pgvector) instead of introducing a new technology.
Default to having everything in one database instance at first, as the overhead of a second instance is often not worth it. Decide carefully when to introduce a new instance (If you need a partner to help you design your setup, contact me. I am up for hire).
What about performance?
This is the biggest argument that vector database startups are shouting from the roof tops: Use us, if you want REALLY good performance. As supabase measured, it turns out that Pinecone (the biggest commercially available dedicated vector database) is actually slower than pgvector (the vector database implementation for PostgreSQL). Also, pgvector gives you more bang for the buck.
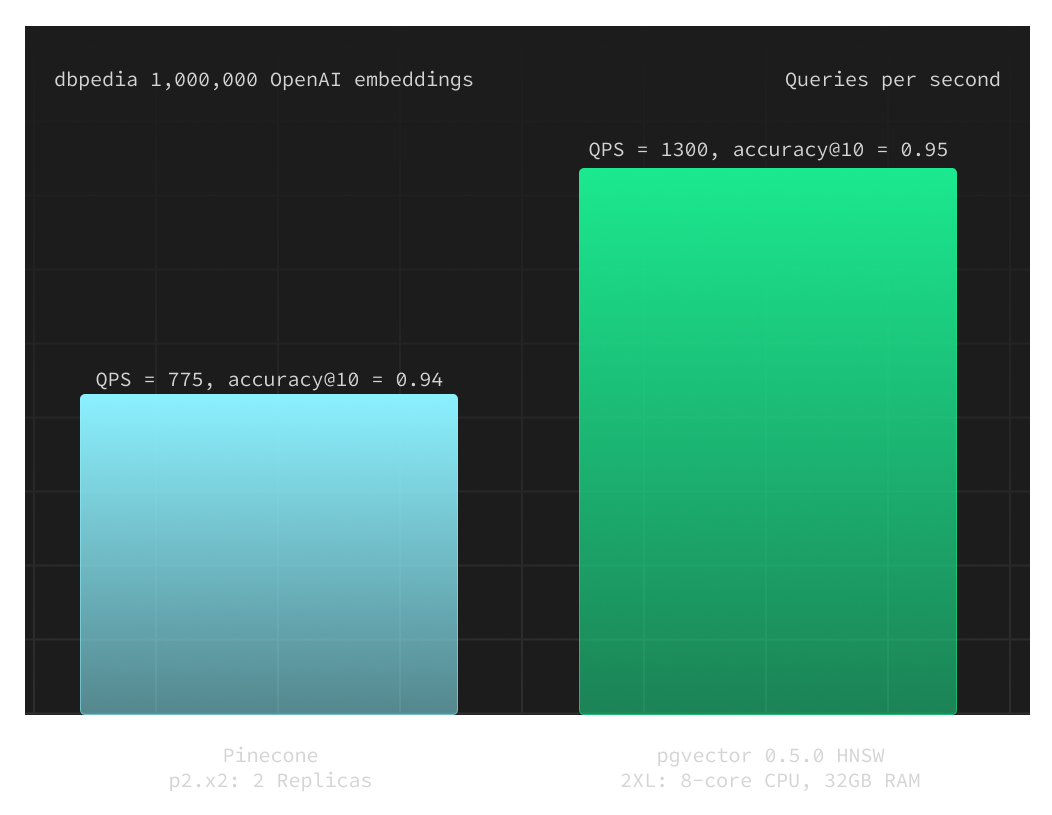
This is only one example, but the important takeaway we can derive from it: The performance of a dedicated vector database is not per-se better than the implementation in a standard database. (After all, the underlying algorithms for indexing and nearest-neighbor algorithms are the same)
Additionally, using a separate vector database introduces more network roundtrip time, which is often a far bigger performance factor than the actual vector lookup.
However, it became evident that the bottleneck in using a closed-source search solution like Pinecone is primarily the latency from network requests, not the search operation itself.
Confident AI on why they switched from Pinecone to pgvector
As you see, also on the performance argument, dedicated vector databases don’t have a significant edge over the database you already use.
There is a point where your workload has a scale, where you actually might benefit from a specialized database. But let’s be honest, I’m quite sure you don’t have that scale, and the downsides outweigh the benefits. If you want to dive even deeper into raw performance, check out the ANN Benchmarks.
Thank you for reading through this entire article, and now repeat after me: “I will use the database I already have”
Let’s use more boring technology.
Highly skilled DevOps/SRE Freelancer
I am Simon, the author of this blog. And I have great news: You can work with me
As DevOps and Infrastructure freelancer, I will help you choose the right Infrastructure technology for your company, fix your cloud problems and support your team in building scalable products.
I work with Golang, Docker, Kubernetes, Google Cloud, AWS and Terraform.
Checkout my CV to learn more or directly contact me via the button below.
